参考リンク#
はじめに#
ニューラルスパース検索は、OpenSearch 2.11で導入された意味的検索の効率的な方法です。これは、意味的技術を使用してクエリを解釈し、従来の検索では見逃される可能性のある用語を処理します。密なモデルは類似の結果を見つけることができますが、正確な一致を見逃すことがあります。ニューラルスパース検索は、意味的類似性と特定の用語の両方を捉えるためにスパース表現を使用し、より包括的な検索ソリューションを提供することで結果の説明と提示を改善します。
背景#
ニューラルスパース検索は、最初にテキスト(クエリまたは文書のいずれか)をより大きな用語のセットに拡張し、それぞれの意味的関連性に基づいて重み付けを行います。次に、Luceneの効率的な用語ベクトル計算を使用して、最高得点の結果を特定します。このアプローチは、インデックスとメモリコストの削減、ならびに計算コストの低下をもたらします。たとえば、k-NN検索を使用した密なエンコーディングは、検索時にRAMコストを7.9%増加させますが、ニューラルスパース検索はネイティブのLuceneインデックスを使用し、検索時のRAMコストの増加を回避します。さらに、ニューラルスパース検索は、密なエンコーディングと比較してはるかに小さなインデックスサイズをもたらします。文書専用モデルは、密なエンコーディングインデックスのわずか10.4%のサイズのインデックスを生成し、バイエンコーダの場合、インデックスサイズは密なエンコーディングインデックスの7.2%です。
これらの利点を考慮して、私たちはニューラルスパース検索をさらに効率的にするために改良を続けています。OpenSearch 2.15では、新しい機能として二相検索パイプラインが導入されました。このパイプラインは、ニューラルスパースクエリ用語を2つのカテゴリに分割します:検索により関連性の高い高得点トークンと、関連性の低い低得点トークンです。最初に、アルゴリズムは高得点トークンを使用して文書を選択し、その後、高得点トークンと低得点トークンの両方を含めてそれらの文書のスコアを再計算します。このプロセスは、最終的なランキングの質を維持しながら、計算負荷を大幅に削減します。
二相アルゴリズム#
二相検索アルゴリズムは、2つの段階で動作します:
初期段階#
アルゴリズムは、モデル推論を使用して、クエリからの高得点トークンを使用して候補文書のセットを迅速に選択します。これらの高得点トークンは、全トークンの中で小さな部分を構成し、重要な重みまたは関連性を持ち、潜在的に関連する文書を迅速に特定することを可能にします。このプロセスは、処理する必要のある文書の数を大幅に削減し、計算コストを低下させます。
再計算段階#
アルゴリズムは、最初の段階で選択された候補文書のスコアを再計算します。このとき、クエリからの高得点トークンと低得点トークンの両方を含めます。低得点トークンは個別には重みが少ないですが、包括的な評価の一部として貴重な情報を提供します。特に、ロングテール用語が全体のスコアに大きく寄与する場合、これによりアルゴリズムは最終的な文書スコアをより正確に決定できます。
文書を段階的に処理することで、このアプローチは計算オーバーヘッドを削減し、精度を維持します。最初の段階での迅速な選択は効率を高め、2番目の段階での詳細なスコアリングは精度を確保します。多くのロングテール用語を処理しても、結果は高品質のままであり、計算効率が著しく改善されます。
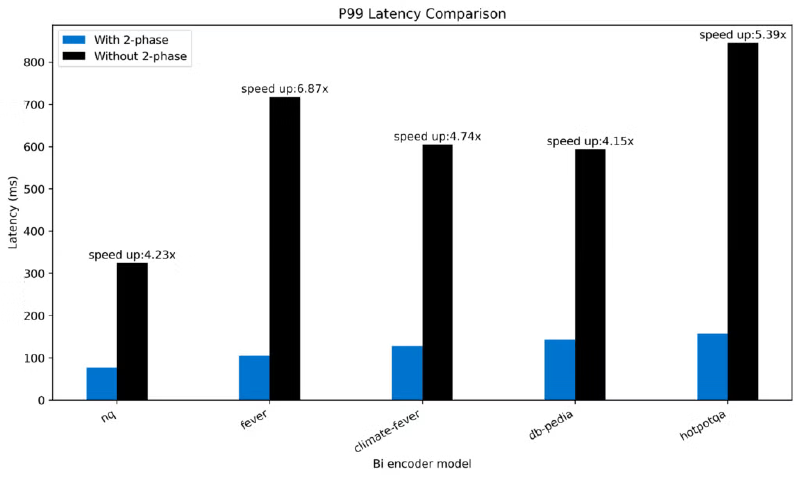
パフォーマンスメトリクス#
データ分布に応じて、二相プロセッサは文書専用モデルで1.22倍から1.78倍の速度向上を達成しました。 ![two-phase-doc-model-p99-latency]](doc-only.png )
また、バイエンコーダモデルで4.15倍から6.87倍の速度向上を達成しました。